#Netezza to Snowflake
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text
The Need to Migrate Data from Netezza to Snowflake
Netezza was introduced in 2003 and became the first data warehouse appliance in the world. Subsequently, there were many “firsts” too – 100 TB data warehouse appliance in 2006 and petabyte data warehouse appliance in 2009.

Netezza has had an amazing run, with unmatched performance due to its hardware acceleration process in field-programmable gate arrays (FPGA). This could be fine-tuned to process intricate queries at blistering speed and scale. Data compression, data pruning, and row-column conversion were all handled optimally by FPGA.
During the lifetime of Netezza, various versions have been launched and all of them have provided high value to the users with simplified management, data pruning, and no need for indexing and partitioning of data. Then, why would users want to migrate data from Netezza to Snowflake?
The cloud-based data warehouse revolution made a huge difference to Netezza as IBM withdrew support. New hardware has not been released since 2014. By doing so IBM has forced Netezza users to abandon the appliance and opt for cloud-based data warehousing solution Snowflake.
There are many benefits of Snowflake for those wanting to shift from Netezza to Snowflake. Snowflake is a premium product, providing a great deal of performance, scalability, and resilience, more than other cloud-based data warehouse solutions.
Additionally, there are many advantages of shifting to the cloud and Snowflake for data management.
· Affordable – Enterprises do not have to invest in additional hardware and software. This is very critical for small industries and start-ups. In this pricing model, users can scale up or down in computing and storage facilities and pay only for the quantum of resources used.
· Reliability – Reliability and uptime of server availability are mostly in excess of 99.9%.
· Deployment speed – Organizations have the leeway to develop and deploy applications almost instantly because of access to unlimited computing and storage facilities.
· Economies of scale – When several organizations share the same cloud resources the costs are amortized for each of them, leading to economies of scale.
· Disaster recovery – When there is an outage in primary databases, the secondary databases in the region are automatically triggered and users can work as usual. When the outage is resolved, the primary databases are restored and updated automatically.
There are two steps in any Netezza to Snowflake data migration strategy.
The first is the lift-and-shift strategy which is used when there is timescale pressures to move away from Netezza with the need to move highly integrated data across existing data warehouse. This is also relevant when a single standalone and independent data mart has to be migrated.
The second is the staged approach. This is applicable when many independent data marts have to be moved independently. The focus here is on new development rather than reworking legacy processes.
Choosing between the two largely depends on such factors as timescale, number of data resources, and types of data types.
0 notes
Text
Automate and Validate Snowflake Data Migration Testing
Simplify all your data testing challenges with Snowflake migration testing and quickly scale testing of your migration to Snowflake Data Warehouse from Netezza, Teradata, Oracle, or any other database using iCEDQ. Learn about snowflake migration and testing and its automation with the iCEDQ automation tool. Visit: http://bit.ly/3IHw3l5
#snowflake testing#snowflake data validation#snowflake migration#snowflake migration tool#netezza to snowflake migration#snowflake data migration#migrating to snowflake#snowflake automation
0 notes
Text
Aqua data studio increase memory

Aqua data studio increase memory professional#
Involved in Development and Testing of UNIX Shell Scripts to handle files from different sources such as NMS, NASCO, UCSW, HNJH, WAM, CPL and LDAP.Strong troubleshooting skills, strong experience of working with complex ETL in a data warehouse environment Extensive experience in database programming in writing Cursors, Stored procedures, Triggers and Indexes.Play the role of technical SME lead the team with respect to new technical design/architecture or modifying current architecture/code.Programming Languages: Visual Basic 6.0, C, C++, HTML, PERL Scripting.ĭelivery Lead/Informatica Technical SME - Lead/Senior Developer/Business Analyst Methodologies: Party Modeling, ER/Multidimensional Modeling (Star/Snowflake), Data Warehouse Lifecycle Operating Systems: MS Windows 7/2000/XP, UNIX, LINUS Other Utilities: Oracle SQL developer 4.0.3.16, Oracle SQL developer 3.0.04, UNIX FTP client, Toad for Oracle 9.0, WinSql 6.0.71.582, Text pad, Agility for Netezza Workbench, Netezza Performance Server, Informatica Admin console, Aqua Data Studio V9 etc. Hands on exposure to ETL using Informatica, Oracle and Unix Scripting with knowledge in Healthcare, Telecommunication and Retail Domains.ĮTL/Reporting Tools: Informatica 10.1.0, Informatica 9.1.0, Informatica 8.6.1, Informatica 8.1.1, Informatica 7.0, Informatica Power Analyzer 4.1, Business Objects Designer 6.5, Cognos8, Hyperion System9.Experience of multiple end to end data warehouse implementations, migration, testing and support assignments.
Aqua data studio increase memory professional#
An experienced Information Technology management professional with over 10 years of comprehensive experience in Data Warehousing / Business Intelligence environments.
0 notes
Text
Why Cloud Native Data Warehouses Are the Way Forward
There are enough statistics and research to show that global cloud adoption is on the rise. Whether it is this report from Statista or even this one from techjury, they all talk about the increased role of cloud in businesses around the world. With the ever-upwards trends in cloud adoption, one also sees an increasing adoption of Cloud Native Warehouses. But, what are Cloud Native Data Warehouses?
Simply put, it is a Cloud Native Data Warehouse that is built entirely off the cloud and cloud services, without using any on-premise aspect. An on-premise warehouse (like Netezza, for instance) has several components deployed on physical servers you manage. There is a case for deploying those to the cloud, but here is the catch- if they are not built up from the cloud (i.e. not cloud native), you will still end up short of utilizing the full power of Cloud Native. The below are some points why that would happen and why Cloud Native is the way forward for Data Warehousing.
Why cloud native is the way forward?
Let us look at a few points on why cloud native is going to be crucial for data warehousing.
Flexibility
Cloud Native DWs bring the same flexibility to the table that cloud is known for. It is the flexibility to do ETLs, deploy, analyze, find and fix Data Quality issues using a cocktail of existing services that YOU choose. Without that flexibility, it becomes cumbersome to decide which tools to go for as tools don’t usually give you just one service. You would need to choose a tool and tweak it to suit your purpose.
Agility
With flexibility, cloud native warehouses also help you hit the market quicker. Some modern warehouses like Snowflake can set you up in a mater of minutes where as traditional warehouses have much longer cycles (both sales and setup) to get up and running.
Cost savings and lower total cost of ownership
This one will always be debatable and we understand that at EoV. There are many supporters of the traditional big data technology mix who would say that cloud can rack up costs far too quickly compared to doing a custom, on-prem/cloud deployment. However, a sound partner’s expertise can help you choose said right cocktail of services to save you money in the long run by always optimizing the total cost of ownership.
Business to the front
You can pretty much manage a modern warehouse like Databricks or Snowflake almost entirely writing SQL scripts. The entire business of writing complex functions, setting up elaborate orchestration, planning for different kinds of ingestion for streams, batches etc. is all gone with Cloud Native DWs. The whole idea is to get the data available and ready for business consumption, as seamlessly as possible. All the layers that the business does not care about really, go back into the background.
Improved data quality
Cloud Native Data Warehouses make it easier for you to track and manage data quality. Whether it is setting up error handling policies, enforcing integrity constraints, processing for duplicate records- you can do it easily once your data is non-siloed and accessible in a single place. That is something that Cloud Native Data Warehouses effectively fulfil.
Maintainability
Traditional, on-premise data warehouses can be extremely difficult to manage. Even to this day, we consider some of the skillsets required to operate the warehouses as rare talents to find. The skills to manage a modern Cloud Native DW is akin to finding a regular DBA with decent SQL skills. The platform owns the entire aspect of infrastructure management.
Support for advanced analytical initiatives (AI/ML)- One of the biggest barriers to effective AI/ML strategies is the presence of high-quality, quickly accessible data. Cloud Native DWs bring that the game thereby powering all our advanced analytical initiatives. There are also many further developments in this arena, the most recent being SnowSpark which add to the capabilities of existing warehouses to support the execution of complex statistical functions. These abilities make Snowflake even more equipped for advanced analytics.
Conclusion
Cloud Native is the most logical way to harness the full power of cloud. When it comes to warehouses, Cloud Native DWs are the most effective in achieving that, allowing you to manage and leverage your data with ease. If you are looking for a partner for your cloud native application development, please get in touch with us now!
0 notes
Text
[PowerBi] Tipos de conexión
Power Bi nos permite nutrirnos de sus múltiples conectores a muy diversos orígenes de datos. Cada uno de ellos tiene particularidades y formas de conexión. Puede que necesitemos instalar un driver o venga por defecto. La realidad es que depende del conector y origen para conocer las formas conexión que contiene.
En éste artículo vamos a presentar las tres formas de conexión que nos provee Power Bi frente a distintos tipos de orígenes de datos. Éstos serán nombrados en ingles para unificar conceptos de Power Bi. Aprendé sobre ellos a continuación.
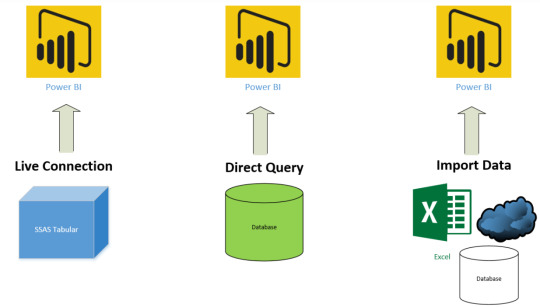
1- Import Data
Éste método funciona cargando todos los datos de la fuente de origen dentro de Power Bi. Importar en Power Bi significa consumir memoria y espacio de disco. Mientras se desarrolla sobre Power Bi Desktop en una computadora la memoria ram y el espacio de disco que consumiría sería el propio. Cuando el informe o conjunto de datos es publicado al portal de Power Bi, la memoria y el disco utilizado sería de una Cloud Machine que provee el Servicio de Power Bi que es invisible para nosotros.
Tengamos en cuenta que si nuestra base de datos tiene 1000 tablas con muchas filas, pero solo cargamos 10 tablas y pocas filas en Power Bi, entonces solo consumiríamos memoria para esas 10 tablas filtradas. La idea de consumir memoria y disco es solo para los datos que queremos trabajar.
Hay una consideración muy importante a tener en cuenta sobre Import Data. Si cargas en Power Bi 100GB de tablas de una base de datos el archivo modelo de Desktop no pesará 100GB. Power Bi tiene un motor de compresión de xVelocidad y funciona con tecnología Column-Store in-memory (dejo en ingles por si quieren leer más al respecto). La forma más conocida para comprobarlo es tener un excel de 1GB y cuando lo importen en Power Bi probablemente termine pesando menos de la mitad del peso original del archivo. Esto sucede por la compresión mencionada antes. Sin embargo, la compresión no será tan buena siempre, la misma depende de varios factores; tipos de datos, cantidad de columnas, etc. Spoiler, más adelante voy a armar un post de como reducir el modelo de datos y ahi podrían aparecer más factores.
Para mantener los datos actualizados en éste método debemos configurar actualizaciones programadas.
Características
Permite usar toda la funcionalidad poderosa de Power BI
Con este método se puede aprovechar mucho características fuertes de Power Bi. Puedes usar Power Query para combinar, transformar y modelar múltiples orígenes de datos o escribir DAX avanzado con Time Intelligence para mejorar objetivos de las visualizaciones. Se pueden aprovechar todos sus componentes con esta forma.
Limitaciones de tamaño
No todo es maravilloso, algo tiene que diferenciarlo de los demás. Esta conexión tiene sus limitaciones. Hay límite con los tamaños. El modelo de datos (aproximadamente el archivo de power bi desktop) no puede pesar más de 1GB. Las áreas de trabajo donde se publican pueden soportar hasta 10GB pero cada archivo no puede superar 1GB. Hay un excepción para las áreas de trabajo con capacidad paga llamada Power Bi Premium que te permite un modelo de 50GB y más aun tocando unas preview features que Christian Wade cuenta sobre escalabilidad, no se trata de esto el post por ende seguiré con los limites. A su vez no es posible procesar una sola tabla que pese más de 10GB. Si una de las tablas a la que nos queremos conectar tiene un peso de 10GB el motor no intentará procesarla sino que avisará al usuario. No todo está perdido y es malo, recordemos que el motor cuenta con una tremenda compresión capas que dejar 1GB de excel en pocos megas. Verán que si quieren llegar a esos limites hablamos de tablas de más de 50 millones de registros aproximadamente. También está limitado en cantidad de actualizaciones programadas por día. Es posible tener hasta 8, que no es poca cosa para un Bi. En caso de Premium puede tener hasta 48.
Es muy rápido
Ésta conexión es la opción más rápida para uso del tablero final. Los datos son cargados en la memoria del servidor y las consultas serán evaluadas dentro de ese modelo comprimido con todos los datos cargado en memoria. De ésta forma nos liberamos de lag y demoras, siempre y cuando sigamos buenas prácticas de Data Modeling que puedes encontrar en ladataweb como el Modelo Estrella.
2- Direct Query
Como el nombre lo indica es una conexión directa al origen de datos. Los datos NO serán almacenados en un modelo comprimido de Power Bi. Power Bi se convierte en la capa de visualización y por cada interacción del usuario sobre dicha capa se construye una consulta automáticamente que consultará los datos para las especificaciones seleccionadas. Power Bi solo almacenará metadata de las tablas. El tamaño del archivo será ínfimo con el cual nunca llegaría a la limitación de 1GB porque los datos no están almacenados en el archivo. Para poder consultar al origen todo el tiempo necesitamos que el origen sea uno que permita recibir consultas. Dejo una lista de ejemplos que permiten esta conexión.
Amazon Redshift
Azure HDInsight Spark (Beta)
Azure SQL Database
Azure SQL Data Warehouse
IBM Netezza (Beta)
Impala (version 2.x)
Oracle Database (version 12 and above)
SAP Business Warehouse
SAP HANA
Snowflake
Spark
SQL Server
Teradata Database
PostgreSQL
Escalabilidad
Como mencioné antes éste método no contendría la limitación de 1GB porque su tamaño de archivo será mínimo. Puedes consultar tablas de más de 10GB y armar modelos de más de 1GB porque no se almacenará en el archivo.
Limitado en funcionalidad
No podremos aprovechar al máximo las funcionalidad de transformación de Power Bi. Solo tendrás dos vistas en Power Bi Desktop, la vista de visualización y la de relaciones. No podrás tener la vista de datos dado que no están cargados.
Respecto a Power Query también está limitado. Solo es posible aplicar un pequeño número de operaciones que en caso contrario el motor mostrará un mensaje que no es posible aplicar la operación.
También está limitado en DAX pero menos que Power Query. No es posible escribir todo tipo de expresiones de columnas y medidas. Varias funciones no son soportadas. Lista completa de permitidas aquí.
Lenta interacción por conectividad
La mayor desventaja de éste método es una lenta conexión al origen de datos. Hay que tener presente que cada interacción del usuario en las visualizaciones es una consulta al motor y la espera en la respuesta para poder reflejarla. Normalmente tenemos más de una visualización y filtros, hay que considerar la respuesta del motor antes de llegar a éste caso. Mi recomendación dice que si demora más de 5 segundos en responder un filtro, no recomiendo el método
No es tiempo real
Para intentar mejorar la velocidad de respuesta del motor Power Bi intentará guardar una cache de respuestas que cambiará cada 15 minutos. Lo que significa que la consulta no es tan directa ni en tiempo real como se espera.
3- Live Connection
La conexión directa es muy similar a Direct Query en la manera que trabaja contra el origen de datos. No almacenará datos en Power Bi y va a consultar el origen de datos cada vez que el usuario lo utilice. Sin embargo, es diferente a las consultas directas. Para aclarar el panorama veamos los orígenes de datos que permiten esta conexión:
SQL Server Analysis Services (SSAS) Tabular
SQL Server Analysis Services (SSAS) Multi-Dimensional
Power BI Service
Porque éstos orígenes de datos ya son por si mismos motores con modelos de datos, Power Bi solo se conectará a éstos sincronizando todos los metadatos (nombres de tablas, columnas, medidas, relaciones). Con éste método el manejo de modelado y transformación de datos será responsabilidad del origen de datos y Power Bi será quien controle la capa superficial de visualizaciones.
Grandes modelos de datos (OLAP o Tabular)
El mayor beneficio de éste método es construir grandes modelos sin temor al limite de 1GB de Power Bi dado que dependerá de la máquina donde esté alojado dejando la capa de modelado para SSAS. Con Tabular se obtiene DAX y con Multi-Dimensional MDX. Con ambos lenguajes es posible llevar a cabo las métricas necesarias en los requerimientos del usuario. Tiene mejores características de modelado que Direct Query porque en ella no disponemos de toda la potencia de SSAS o DAX para ayudarnos.
Solo visualizaciones, nada de Power Query
Una posible desventaja es que este método no permitirá el ingreso al editor de consultas para utilizar Power Query. Con éste método solo tendremos la vista de visualizaciones para construir informes. No es del todo una desventaja porque los motores modernos de SSAS (compatibilidad 1400+) permiten usar Power Query.
Medidas en los reportes
Una Live Connection tendrá la posibilidad de jugar un poco con DAX del lado de medidas en Power Bi y no solamente por parte del origen tabular (recordemos que solo tabular tiene DAX). Sin embargo, para mantener la consistencia de un modelo, lo mejor sería no crear medidas sobre Power Bi sino mantener todas ellas en el origen Tabular para que todos los que se conecten dispongan de ellas.
Resumen en una foto
Resumen Tabla - de Power Bi Tips
table { border-collapse: collapse; width: 100%; border:1; } td, thead { text-align: left; padding: 8px; } tr:nth-child(even) {background-color: #f2f2f2;} th { text-align: left; padding: 8px; background-color: #301f09; color: white; }
Capability Import DirectQuery Size Up to 1 GB per dataset No limitation Data Source Import data from Multiple sources Data must come from a single Source Performance High-performance query engine Depends on the data source response for each query Data Change in the underlying data Not Reflected. Required to do a Manual refresh in Power BI Desktop and republish the report or Schedule Refresh Power BI caches the data for better performance. So, it is necessary to Refresh to ensure the latest data Schedule Refresh Maximum 8 schedules per day Schedule often as every 15 mins Power BI Gateway Only required to get latest data from On-premise data sources Must require to get data from On-premise data sources Data Transformations Supports all transformations Supports many data transformations with some limitations Data Modelling No limitation Some limitations such as auto-detect relationships between tables and relationships are limited to a single direction. Built-in Date Hierarchy Available Not available DAX expressions Supports all DAX functions Restricted to use complex DAX functions such as Time Intelligence functions. However, if there is a Date table available in the underlying source then it supports Clustering Available Not available Calculated Tables Available Not supported Quick Insights Available Not available Q&A Available Not available Change Data Connectivity mode Not possible to change Import to DirectQuery Possible to change DirectQuery to Import
Ahora que conocemos las diferencias podemos estar seguros de como conectarnos a nuestros orígenes. Dependerá de ellos para conocer el tipo de conexión a utilizar porque para cada caso podría ajustarse uno distinto.
¿Qué te pareció? ¿Aprendiste la diferencia o estás más confundido?
#powerbi#power bi#power bi direct query#power bi live connection#power bi import data#power bi connections#power bi tutorial#power bi SSAS#power bi training#power bi jujuy#power bi cordoba#power bi argentina
0 notes
Photo

Top MNC Companies are Hiring. Get the Right Job for Your Career. Find Better with itconsultant4u.com
Are you a Professional in Cloud Migration? Then what are you waiting for here is an opportunity to work with Amazon India
Job Designation: Cloud Migration Specialist - Database
Company: Amazon
Skills: Cloud Platform AWS, Azure, Google, etc., databases like Oracle, SQL Server, PostgreSQL, Teradata, SQL server, etc.,
Experience Range: 4+ Years Of Experience
Location: Hyderabad
Educational Requirements:
Bachelor’s degree in Information Science / Information Technology, Computer Science, Engineering, Mathematics, Physics, or a related field.
Job Description:
Implementing experience with primary AWS services (EC2, ELB, RDS, Lambda, API Gateway Route53 & S3)
AWS Solutions Architect Certified
Experience with other OLTP databases like Oracle, PostgreSQL, SQL Server, etc
Experience in writing and migration Stored Procedures and functions
Scripting language (bash, Perl, python)
Experience in ETL workflow management
Experience in non-relational databases – DynamoDB, Mongo, etc.
Experience in MPP databases- Redshift, Netezza, Teradata, Snowflake.
Apply Now Here: http://bit.ly/cloud-migration-specialist-amazon
#cloud migration#cloud jobs#itconsultant4u#it consulting#it consultancy#it consultant#it career#job alert#job vacancies#job opportunities#hyderabad jobs
0 notes
Text
Need MicroStrategy Developer
Role: Microstrategy Developer Job Description: 5+ years of direct Microstrategy experience and overall 8+ years of DW/BI experience Competencies with RDBMS such as Oracle, Netezza, SQL Server, MYSQL. Competencies in database architectures such as relative, star and snowflake schemas. Ability to thoroughly research subjects to support reporting application project wor... Need MicroStrategy Developer from Job Portal https://www.jobisite.com/sj/id/9049488-Need-MicroStrategy-Developer
0 notes
Link
Quickly scale testing of your migration to Snowflake Data Warehouse from Netezza, Teradata, Oracle, or any other database using iCEDQ.
0 notes
Text
Need MicroStrategy Developer
Role: Microstrategy Developer Job Description: 5+ years of direct Microstrategy experience and overall 8+ years of DW/BI experience Competencies with RDBMS such as Oracle, Netezza, SQL Server, MYSQL. Competencies in database architectures such as relative, star and snowflake schemas. Ability to thoroughly research subjects to support reporting application project wor... Need MicroStrategy Developer from http://bit.ly/2vrKvqR
0 notes
Text
Senior ETL Developer
Job Title :Senior ETL Developer No of Openings :2 Position Type : 8 months Contract City :Columbus State :OH Required Skills : SQL, Unix, Shell, Korn, Teradata or Netezza or snowflake or green plum Job Description : ETL Developers in Columbus, Ohio who have experience or exposure to ODI or Ab Initio. Responsibilities: ? Determines feasibility of requests, identifies best approach to provide technology solutions to meet business needs and provide detailed estimations (time, cost, resources) ? Works with solution engineer to design and architect solutions and lead the implementation and delivery ? Provides recommendations for ente...
Source: https://www.jobisite.com/sj/id/9047744-Senior-ETL-Developer
0 notes
Text
Senior ETL Developer
Job Title :Senior ETL Developer No of Openings :2 Position Type : 8 months Contract City :Columbus State :OH Required Skills : SQL, Unix, Shell, Korn, Teradata or Netezza or snowflake or green plum Job Description : ETL Developers in Columbus, Ohio who have experience or exposure to ODI or Ab Initio. Responsibilities: ? Determines feasibility of requests, identifies best approach to provide technology solutions to meet business needs and provide detailed estimations (time, cost, resources) ? Works with solution engineer to design and architect solutions and lead the implementation and delivery ? Provides recommendations for ente... from Job Portal https://www.jobisite.com/sj/id/9047744-Senior-ETL-Developer
0 notes